1. Estimator 이해 및 fit(), predict() 메서드
Note
- 사이킷런은 ML 모델 학습을 위해서
fit(), 예측을 위해predict()메서드를 제공- 지도학습의 주요 유형인 분류(Classification)와 회귀(Regression)를 위한 다양한 알고리즘을 지원
- 분류 알고리즘을 구현한 클래스를는
Classifier로, 회귀 알고리즘을 구현한 클래스는Regressor로 지칭- 이러한
Classifier와Regressor를 포함한 모든 모델 클래스는Estimator클래스로 통칭됨- 모든
Estimator는fit()을 통해 학습하고,predict()를 통해 예측을 수행
cross_val_score()와 같은evaluation함수,GridSearchCV와 같은 하이퍼 파라미터 튜닝을 지원하는 클래스의 경우 이Estimator를 인자로 받음- 인자로 받은
Estimator에 대해서cross_val_score(),GridSearchCV.fit()함수 내에서 이 Estimator의fit()과predict()를 호출해서 평가를 하거나 하이퍼 파라미터 튜닝을 수행하는 것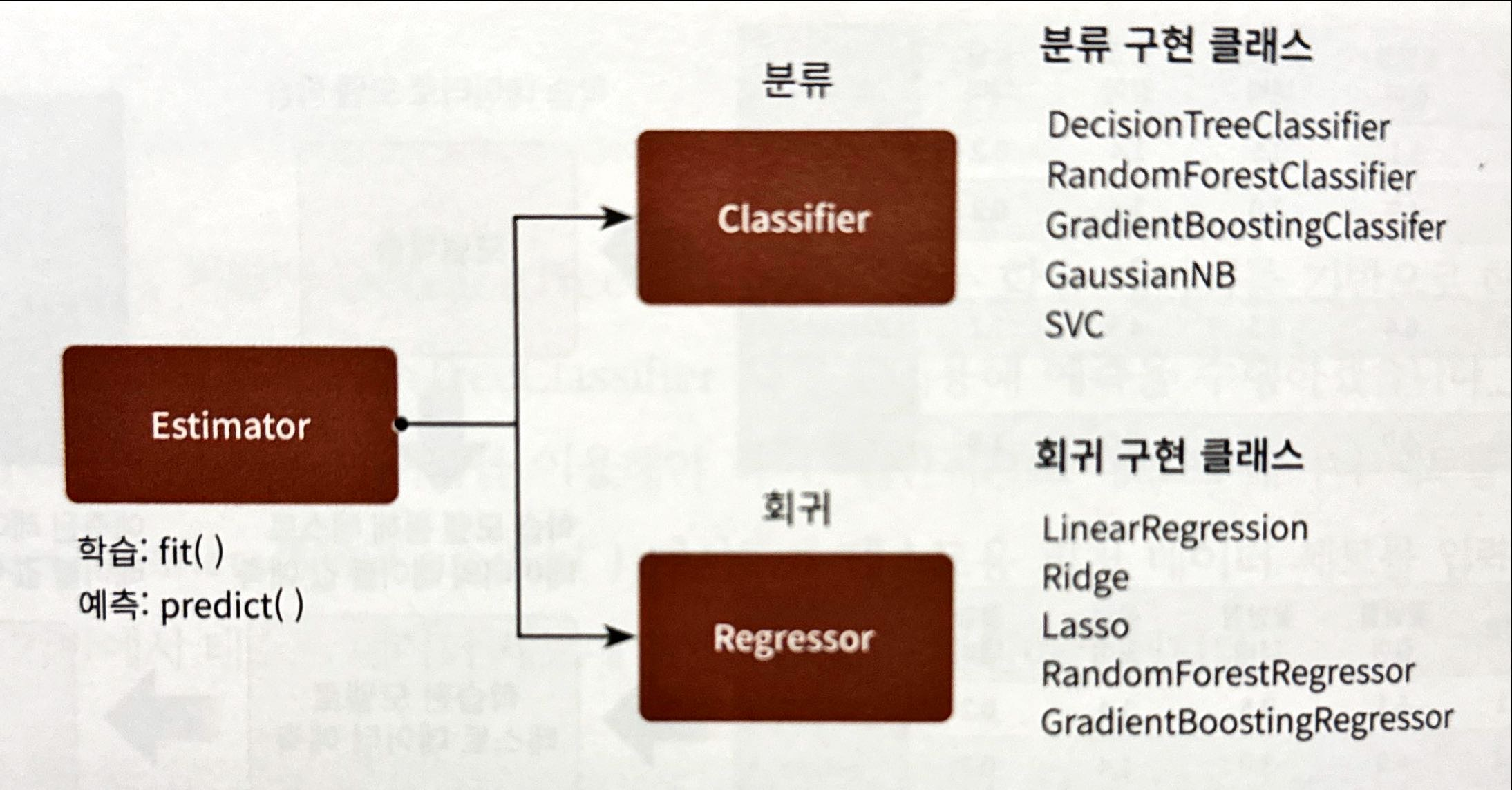
2. 사이킷런의 주요 모듈



Check
일반적으로 머신러닝 모델을 구축하는 주요 프로세스는 feature의 가공, 변경, 추출을 수행하는 feature processing, ML 알고리즘 학습/예측 수행, 그리고 모델 평가의 단계를 반복적으로 수행하는 것
3. 내장된 예제 데이터 세트
Note
사이킷런에는 별도의 외부 웹사이트에서 데이터 세트를 내려받을 필요 없이 예제로 활용할 수 있는 간단하면서도 좋은 데이터 세트가 내장돼 있음
- 사이킷런에 내장 되어 있는 데이터 세트는 분류나 회귀를 연습하기 위한 예제 용도의 데이터 세트와 분류나 클러스터링을 위해 표본 데이터로 생성될 수 있는 데이터 세트로 나뉘어 짐
a. 분류/회귀 연습용 예제 데이터
| API 명 | 설명 |
|---|---|
datasets.load_boston() | 회귀 용도이며, 미국 보스턴의 집 feature들과 가격에 대한 데이터 세트 |
datasets.load_breast_cancer() | 분류 용도이며, 위스콘신 유방암 feature들과 악성/음성 label 데이터 세트 |
datasets.load_diabetes() | 회귀 용도이며, 당뇨 데이터 세트 |
datasets.load_digits() | 분류 용도이며, 0에서 9까지 숫자의 이미지 픽셀 데이터 세트 |
datasets.load_iris() | 분류 용도이며, 붓꽃에 대한 feature를 가진 데이터 세트 |
fetch계열의 명령은 데이터의 크기가 커서 패키지에 처음부터 저장돼 있지 않고 인터넷에서 내려받아 홈 디렉터리 아래의 scikit_learn_data라는 서브 디렉터리에 저장한 후 추후 불러들이는 데이터 (최초 사용 시에 인터넷에 연결돼 있지 않으면 사용 불가)fetch_covtype(): 회귀 분석용 토지 조사 자료fetch_20newsgroups(): 뉴스 그룹 텍스트 자료fetch_olivetti_faces(): 얼굴 이미지 자료fetch_lfw_people(): 얼굴 이미지 자료fetch_lfw_pairs(): 얼굴 이미지 자료fetch_rcv1(): 로이터 뉴스 말뭉치fetch_mldata(): ML 웹사이트에서 다운로드
b. 분류/클러스터링을위한 표본 데이터 생성기
| API 명 | 설명 |
|---|---|
datasets.make_classifications() | 분류를 위한 데이터 세트를 만듦. 특히 높은 상관도, 불필요한 속성 등의 노이즈 효과를 위한 데이터를 무작위로 생성 |
datasets.make_blobs() | 클러스터링을 위한 데이터 세트를 무작위로 생성. 군집 지정 개수에 따라 여러 가지 클러스터링을 위한 데이터 세트를 쉽게 만들어 줌 |
c. 분류나 회귀를 위한 연습용 예제 데이터의 구성
- 사이킷런에 내장된 이 데이터 세트는 일반적으로 딕셔너리 형태로 되어 있음
- key는 보통 data, target, target_name, feature_names, DESCR로 구성돼 있음
data(ndarray) : feature의 데이터 세트target(ndarray) : 분류 시 label 값, 회귀일 때는 숫자 결괏값 데이터 세트target_names(ndarray or list) : 개별 label의 이름feature_names(ndarray or list) : feature의 이름DESCR(string) : 데이터 세트에 대한 설명과 각 feature의 설명
붓꽃 데이터 세트의 구성
from sklearn.datasets import load_iris
iris_data = load_iris()
print(type(iris_data))load_iris()의 API 반환 결과는sklearn.utils.Bunch클래스로 파이썬 딕셔너리 자료형과 유사
keys = iris_data.keys()
print('붓꽃 데이터 세트의 키들:', keys)
>>> 붓꽃 데이터 세트의 키들: dict_keys(['data', 'target', 'frame', 'target_names', 'DESCR', 'feature_names', 'filename', 'data_module'])-
다음 그림은
load_iris()가 반환하는 붓꽃 데이터 세트의 각 키가 의미하는 값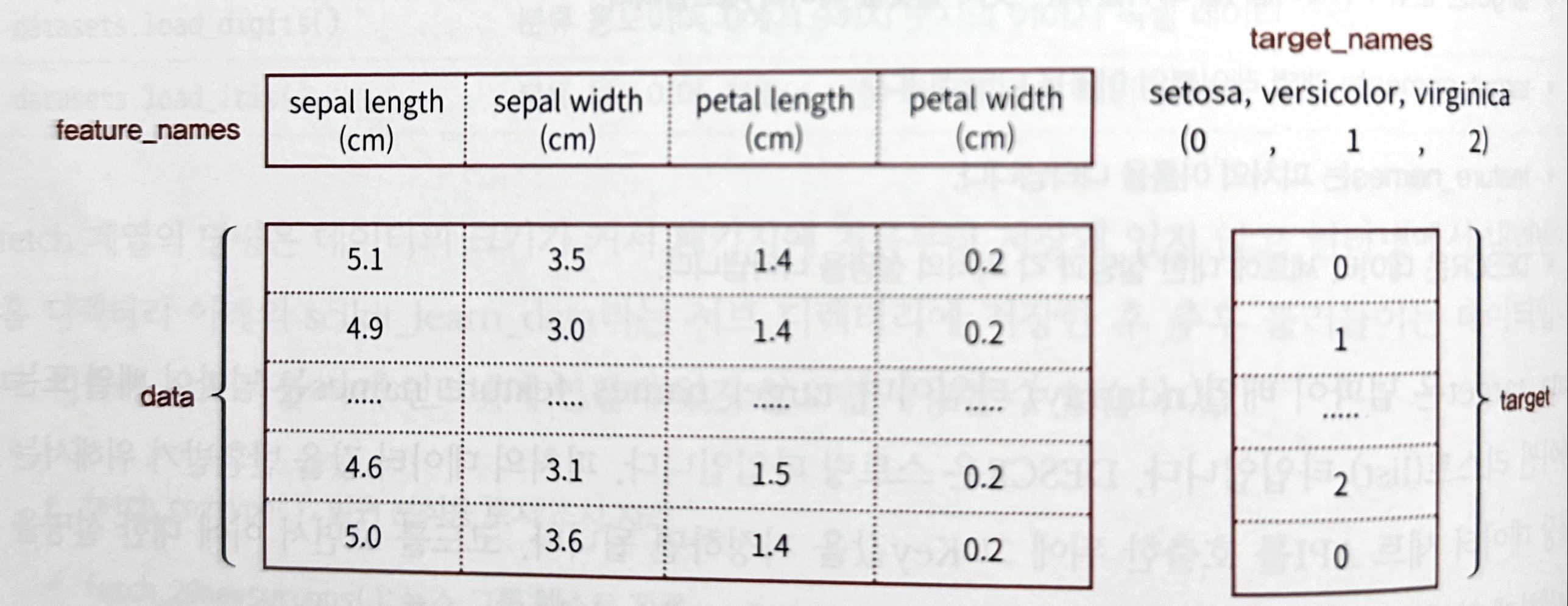
-
feature_names,target_name,data,target의 values 확인
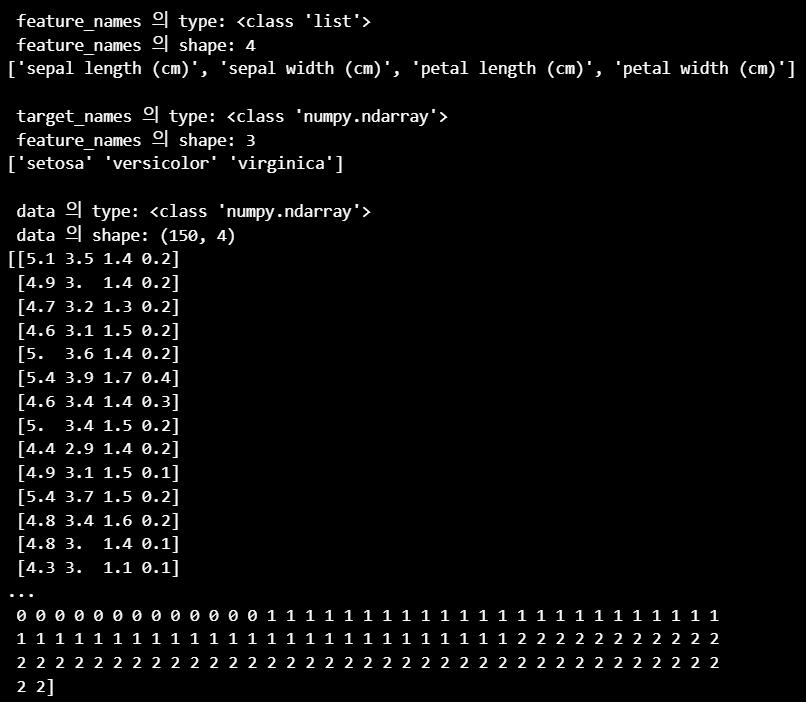
print('\n feature_names 의 type:',type(iris_data.feature_names))
print(' feature_names 의 shape:',len(iris_data.feature_names))
print(iris_data.feature_names)
print('\n target_names 의 type:',type(iris_data.target_names))
print(' feature_names 의 shape:',len(iris_data.target_names))
print(iris_data.target_names)
print('\n data 의 type:',type(iris_data.data))
print(' data 의 shape:',iris_data.data.shape)
print(iris_data['data'])
print('\n target 의 type:',type(iris_data.target))
print(' target 의 shape:',iris_data.target.shape)
print(iris_data.target)