scikit-learn을 통한 첫 번째 머신러닝 모델
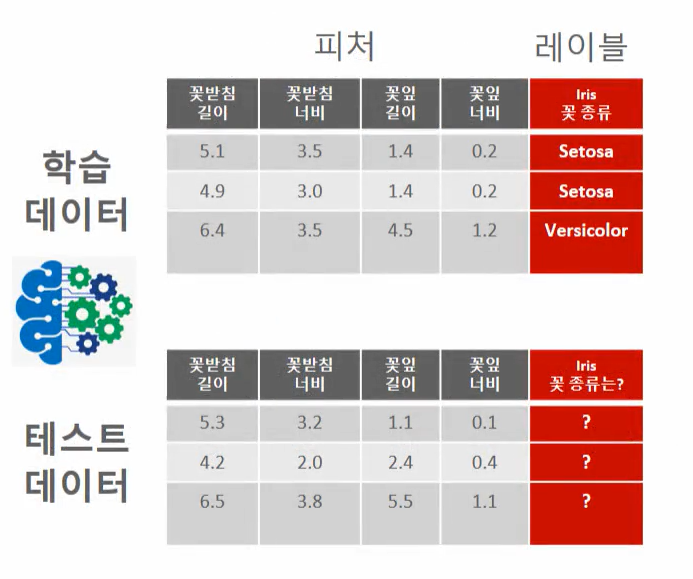
붓꽃 데이터 세트 → 붓꽃의 품종을 **분류(Classification)**하는 것 붓꽃 데이터 세트 : 꽃잎의 길이와 너비, 꽃받침의 길이와 너비 feature를 기반으로 꽃의 품종 예측

- 분류(Classification)는 대표적인 지도학습(Supervised Learning) 방법
- 지도학습이란?
- 학습을 위한 다양한 feature(데이터를 설명하는 입력변수)와 분류 결정값인 label(정답) 데이터로 모델을 학습한 뒤, 별도의 테스트 데이터 세트에서 미지의 label을 예측하는 방법
- 즉, 지도학습은 명확한 정답이 주어진 데이터를 먼저 학습한 뒤 미지의 정답을 예측하는 방식
- 이때 학습을 위해 주어진 데이터 세트 → 학습 데이터 세트, 머신러닝 모델의 예측 성능을 평가하기 위해 별도로 주어진 데이터 세트 → 테스트 데이터 세트로 지칭
1. scikit-learn에서 사용할 모듈 import
from sklearn.datasets import load_iris
from sklearn.tree import DecisionTreeClassifier
from sklearn.model_selection import train_test_split- 사이킷런 패키지 내의 모듈명은 sklearn으로 시작하는 명명규칙 존재
sklearn.datasets: 사이킷런에서 자체적으로 제공하는 데이터 세트를 생성하는 모듈의 모임- 붓꽃 데이터 세트를 생성하는 데는
load_iris()를 이용
- 붓꽃 데이터 세트를 생성하는 데는
sklearn.tree: tree 기반 ML 알고리즘을 구현한 클래스의 모임- ML 알고리즘은 의사 결정 트리(Decision Tree) 알고리즘으로, 이를 구현한
DecisionTreeClassifier를 적용
- ML 알고리즘은 의사 결정 트리(Decision Tree) 알고리즘으로, 이를 구현한
sklearn.model_selection: 학습 데이터와 검증 데이터, 예측 데이터로 데이터를 분리하거나 최적의 하이퍼 파라미터로 평가하기 위한 다양한 모듈의 모임- 하이퍼 파라미터(Hyperparameter) : 머신러닝 알고리즘별로 최적의 학습을 위해 직접 입력하는 파라미터 (머신러닝 알고리즘의 성능을 튜닝할 수 있음)
- 데이터 세트를 학습 데이터와 테스트 데이터로 분리하는 데는
train_test_split()함수를 사용
2. 붓꽃 데이터 세트 로딩 → DataFrame 변환
import pandas as pd
# 붓꽃 데이터 세트를 로딩합니다.
iris = load_iris()
# iris.data는 Iris 데이터 세트에서 피처(feature)만으로 된 데이터를 numpy로 가지고 있습니다.
iris_data = iris.data
# iris.target은 붓꽃 데이터 세트에서 레이블(결정 값) 데이터를 numpy로 가지고 있습니다.
iris_label = iris.target
print('iris target값:', iris_label)
print('iris target명:', iris.target_names)
# 붓꽃 데이터 세트를 자세히 보기 위해 DataFrame으로 변환합니다.
iris_df = pd.DataFrame(data=iris_data, columns=iris.feature_names)
iris_df['label'] = iris.target
iris_df.head(3)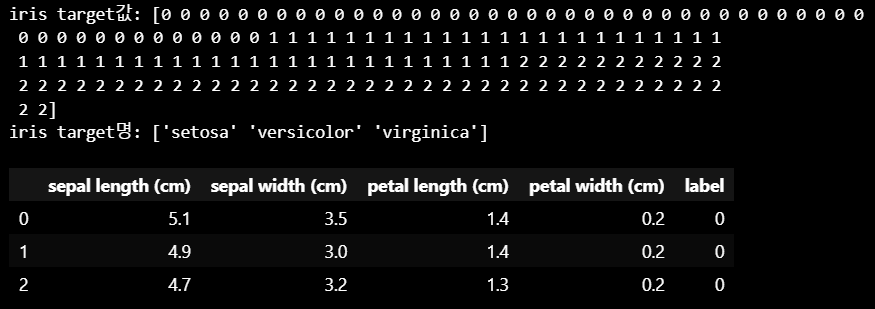
- feature : sepal length, sepal width, petal length, petal width
- label : 0 (setosa 품종), 1 (versicolort 품종), 2 (virginica 품종)
3. 학습용 데이터와 테스트용 데이터 분리
X_train, X_test, y_train, y_test = train_test_split(iris_data, iris_label,
test_size=0.2, random_state=11)- 학습용 데이터와 테스트용 데이터는 반드시 분리해야 함
- 학습 데이터로 학습된 모델이 얼마나 뛰어난 성능을 가지는지 평가하려면 테스트 데이터 세트가 필요하기 때문!
- 이를 위해서 사이킷런은
train_test_split()API를 제공 train_test_split(): 사이킷런에서 제공하는 데이터 분할 함수, train set와 test set를 나눌 때 사용test_size파라미터 : 입력값의 비율로 쉽게 분할test_size = 0.2: 전체 데이터 중 테스트 데이터가 20%, 학습 데이터가 80%로 데이터 분할
- 첫 번째 파라미터인
iris_data는 feature 데이터 세트, 두 번째 파라미터인iris_label은 label 데이터 세트
4. Decision Tree를 이용한 학습과 예측
# DecisionTreeClassifier 객체 생성
dt_clf = DecisionTreeClassifier(random_state=11)
# 학습 수행
dt_clf.fit(X_train, y_train)- 먼저 사이킷런의 의사 결정 트리 클래스인
DecisionTreeClassifier를 객체로 생성random_state=11은 항상 동일한 모델이 생성되도록 보장해주는 것
- 생성된
DecisionTreeClassifier객체의fit()메서드에 학습용 feature 데이터 속성과 label 값 데이터 세트를 입력해 호출하면 학습을 수행
# 학습이 완료된 DecisionTreeClassifier 객체에서 테스트 데이터 세트로 예측 수행.
pred = dt_clf.predict(X_test)- 예측은 반드시 학습 데이터가 아닌 다른 데이터를 이용해야 하며, 일반적으로 테스트 데이터 세트를 이용
DecisionTreeclassifier객체의predict()메서드에 테스트용 feature 데이터 세트를 입력해 호출 → 학습된 모델 기반에서 테스트 데이터 세트에 대한 예측값을 반환
5. 예측 성능 평가
from sklearn.metrics import accuracy_score
print(f'예측 정확도: {accuracy_score(y_test, pred):.4f}')
>>> 예측 정확도: 0.9333- 일반적으로 머신러닝 모델의 성능 평가 방법은 여러 가지가 있으나, 여기서는 정확도를 측정해봄
- 정확도 (accuracy) : 예측 결과가 실제 label 값과 얼마나 정확하게 맞는지를 평가하는 지표
- 사이킷런은 정확도 측정을 위해
accuracy_score()함수 제공 - 첫 번째 파라미터로 실제 label 데이터 세트, 두 번째 파라미터로 예측 label 데이터 세트 입력
- 사이킷런은 정확도 측정을 위해
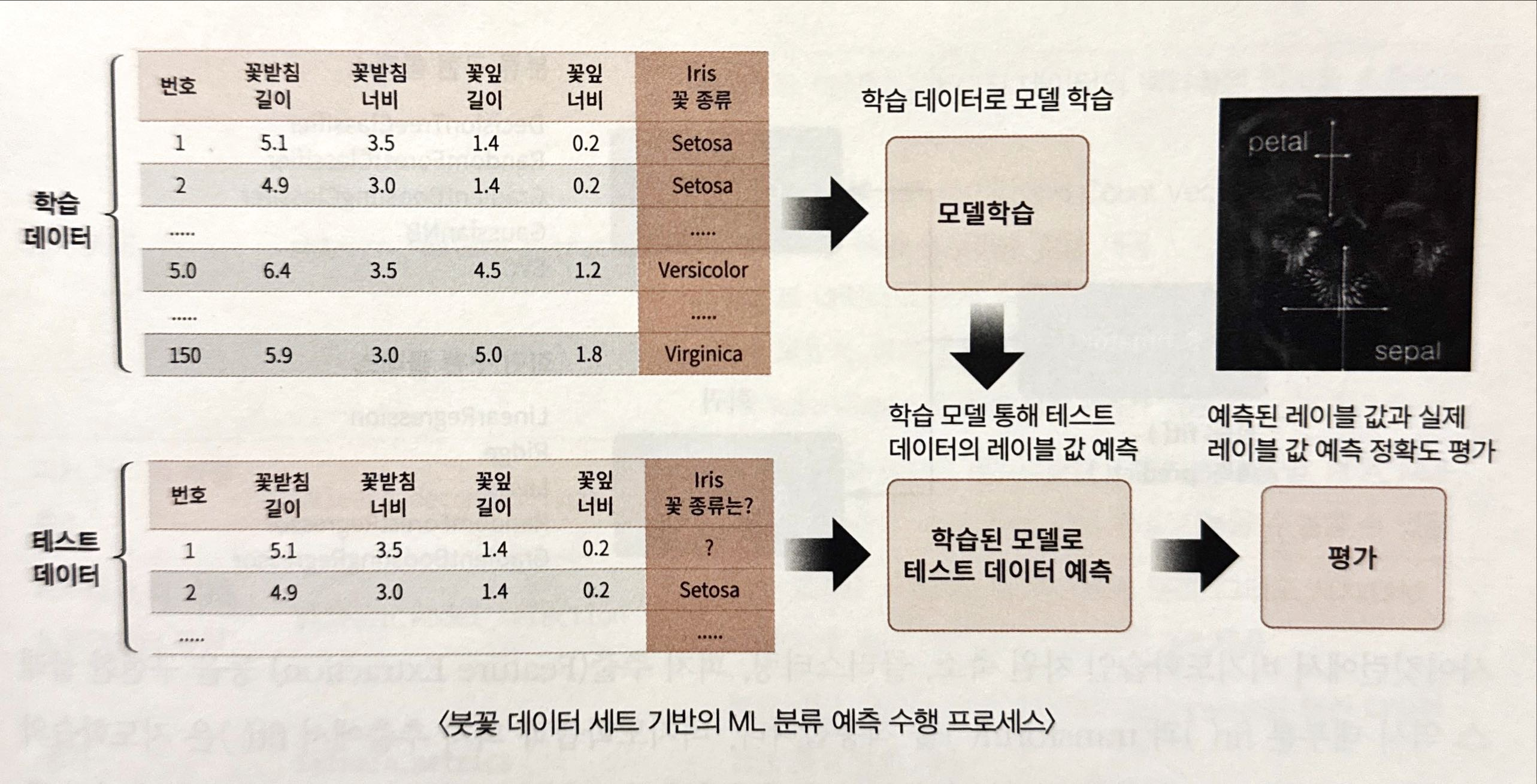
붓꽃 데이터 세트로 분류를 예측한 process
- 데이터 세트 분리 : 데이터를 학습 데이터와 테스트 데이터로 분리
- 모델 학습 : 학습 데이터를 기반으로 ML 알고리즘을 적용해 모델을 학습
- 예측 수행 : 학습된 ML 모델을 이용해 테스트 데이터의 분류 (즉, 붓꽃 종류)를 예측
- 평가 : 예측된 결괏값과 테스트 데이터의 실제 결괏값을 비교해 ML 모델 성능을 평가